Intro to Text as Data
Breaking down a text into smaller units of analysis lets us see patterns and approach from different points of entry.
In text analysis (also referred to as text mining), units of analysis tend to be groupings of text (broken up as discrete books, documents, poems, etc.), and words. Much of the time spent doing text analysis research is spent preparing text so that these smaller units of analyses can be accessed by the digital tools we use.
Defining Units of Analysis

Usually when people analyze text, they are interested in words (i.e. word frequency, order, etc.).
Therefore, a primary part of preparing your text for research is making sure the words in your corpus are identifiable units of measurement.
Thinking of Text as a “Bag of Words”
Structured Data vs. Unstructured Data
- Structured data: Data with fixed fields (key/value pairs, relations)
- Example: csv of names, phone numbers, dates, zip codes
- Unstructured data: No computer-readable structure or relationships between units of analysis
- Example: un-coded text
In textual research in the digital humanities, usually we are working with unstructured data.
File Type
Generally, there is a distinction between two broad types of computer files: text or binary.
- Text Files contain only bytes that represent text characters organized in lines (e.g.
a,B, space, tab, line breaks, etc.). They can be opened with a text editor to see the characters. For example, TXT, CSV, HTML, or MD files. - Binary Files contain bytes that are NOT text characters. They will require software (other than a text editor) that can correctly interpret the bytes. For example, a JPG image, MP3 sound file, or a ZIP compressed folder.
Usually, when talking about text files when doing text analysis, we mean plain text: text files that contain only Unicode-encoded characters like a, 1, <, !, etc.
Some characters might be “hidden” control characters, such as tabs and line breaks.
(adapted from Evan Williamson’s File Types Notes)
Having text in this simple format enables it to be manipulated as data. However, most textual content is locked in the printed page, so the first step is to extract the information from digitized images.
OCR (Optical Character Recognition)
OCR identifies printed or handwritten text characters in digital images of physical documents. Once translated by the OCR software, the characters can be recognized as text by the computer, allowing a document’s content to be processed and manipulated as data.
Traditional OCR Workflow
- Digitization (make high quality scans)
- Image preprocessing (deskew, scale remove borders, high-pass filter)
- Layout detection and segmentation (identify organization and lines of text to pass to OCR)
- OCR (feature extraction)
- Text post-processing (adaptive recognition, lexicons, co-occurrence, noise reduction)
(adapted from Evan Williamson’s OCR: Workflows and Data)


Try it yourself: Tesseract is an open-source OCR software. If you have access to the proprietary Adobe Acrobat software, you can use it to extract text as well.
Where to Find Texts
Copyright
Depending on what you’re going to do with your texts, you’ll need to pay attention to whether or not they are in the public domain. Texts that are no longer under copyright are usually easier to use for analytical research because they have a greater likelihood of already being digitized. (Of course, this also has the effect of skewing text research in DH so that it focuses more on older literary works.)
A good resource to use if you’re wondering whether something is under copyright is Cornell University Library’s Copyright Information Center. Currently, most works published before 1925 are in the public domain.
Digitized Text
- Project Gutenberg
- Full text of thousands of free books. Text is usually fairly clean, but often little bibliographic information.
- Archive.org
- Full texts and scans of books, lots of different download options from epub to pdf, to plain text.
- HathiTrust
- Millions of digitized books, public domain and copyrighted. Cleanliness of text varies. More advanced features require institutional membership.
Activity: Find a Text
- Go to https://archive.org/details/waldenorlifeinwo1854thor/page/n3, the record for an 1854 edition of Henry David Thoreau’s Walden on Archive.org
- Take a look at the download options on the right side of the page. At the bottom of this box, click on
SHOW ALL - Right click on the .txt file (
waldenorlifeinwo1854thor_djvu.txt). In the drop-down menu selectSave link as.... Name the filewaldenand save it to a place on your computer where you can find it again. - Find your newly-saved text file and open it in Visual Studio Code.
- Take a moment to refer back to the digitized pages of the book. How are the layout and content of the original images transformed in the text file you just created? What’s missing?
Text Cleaning
After you’ve OCRed your text and transferred it to plain text format, you will likely discover errors in your new text file(s).
OCR is not perfect.
Especially if you are using older texts, you might encounter problems such as your s’s looking like f’s:

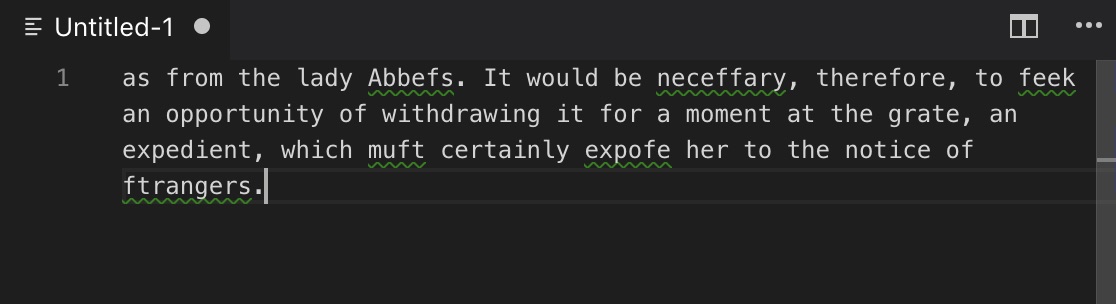
Find and replace might help with some of these problems, but for others you need a stronger tool. In this case, a lot of people will use Regular Expressions.
Regular Expressions are sequences of symbols and characters expressing a string to be searched for within a text. They can get very complicated and are not very intuitive, so we won’t spend too much time with them now, but we’ll apply a few here just to get a taste.
A good resource for learning regular expressions is RegExr, and a good cheat sheet is Regex cheat sheet
Activity: Clean Your Text With Regular Expressions
- Open walden.txt in Visual Studio Code (if you’ve misplaced it you can also download it here: walden.txt)
- Delete the front matter
- Click on
Edit > Find(cmd + Fon mac orctl + Fon pc) to open a search box - Make sure your regular expression function is turned on
Remove multi-word titles and page numbers:
- In the search box, type:
[A-Z]+\s+[A-Z]+\W+\s\d+[A-Z]+finds one or more capital letter characters,\sfinds a space,\Wfinds a special character,\d+finds one or more digits (numbers)
- Using the Find and Replace function on your editor, replace all instances of this text pattern.
Remove multi-word titles:
[A-Z]+\s+[A-Z]+\W+
Remove single word titles and page numbers:
[A-Z]+\W\s\d+
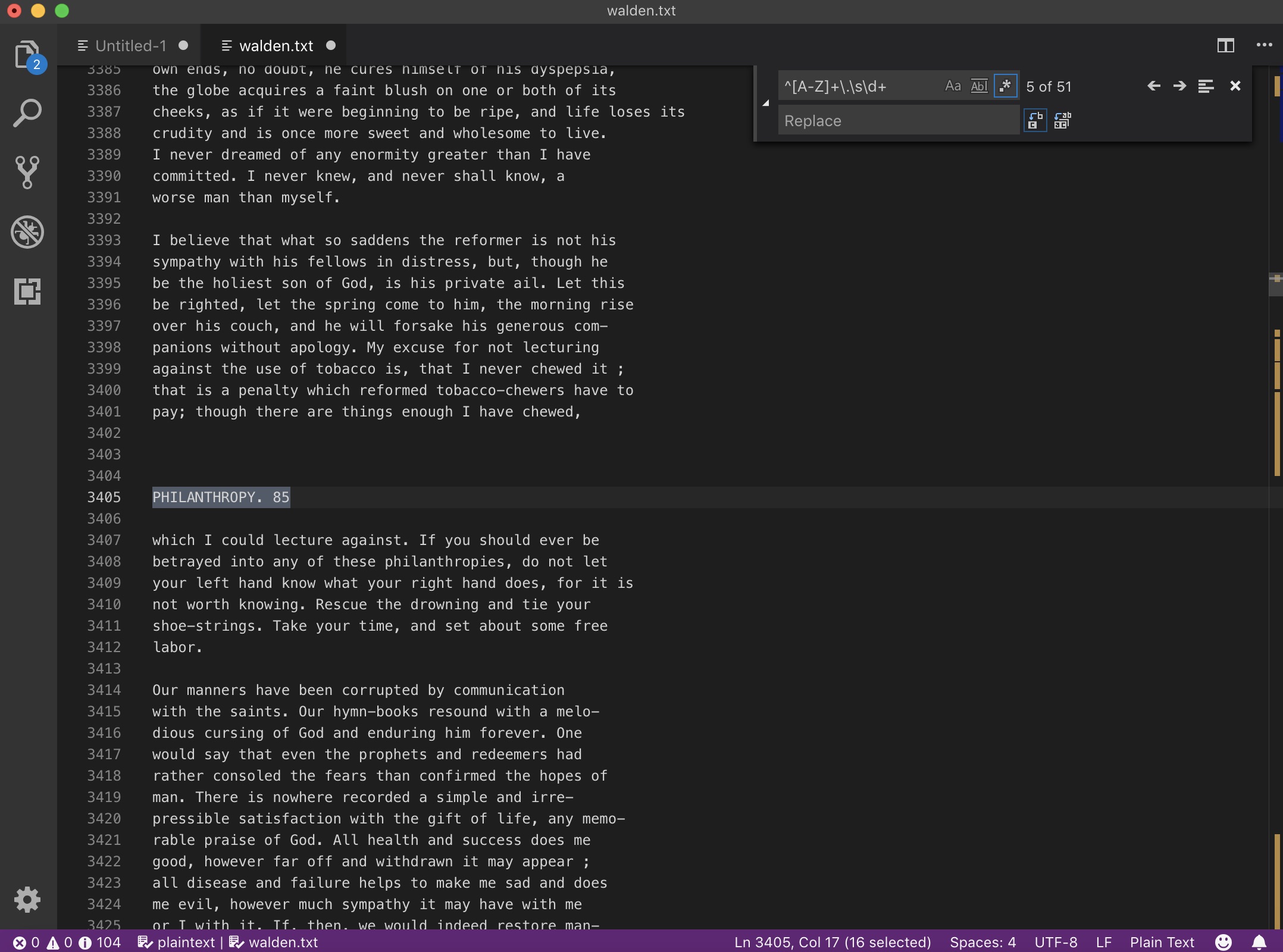
Remove Walden titles and page numbers on left-hand pages:
^\d+\s[A-Z]+\W+
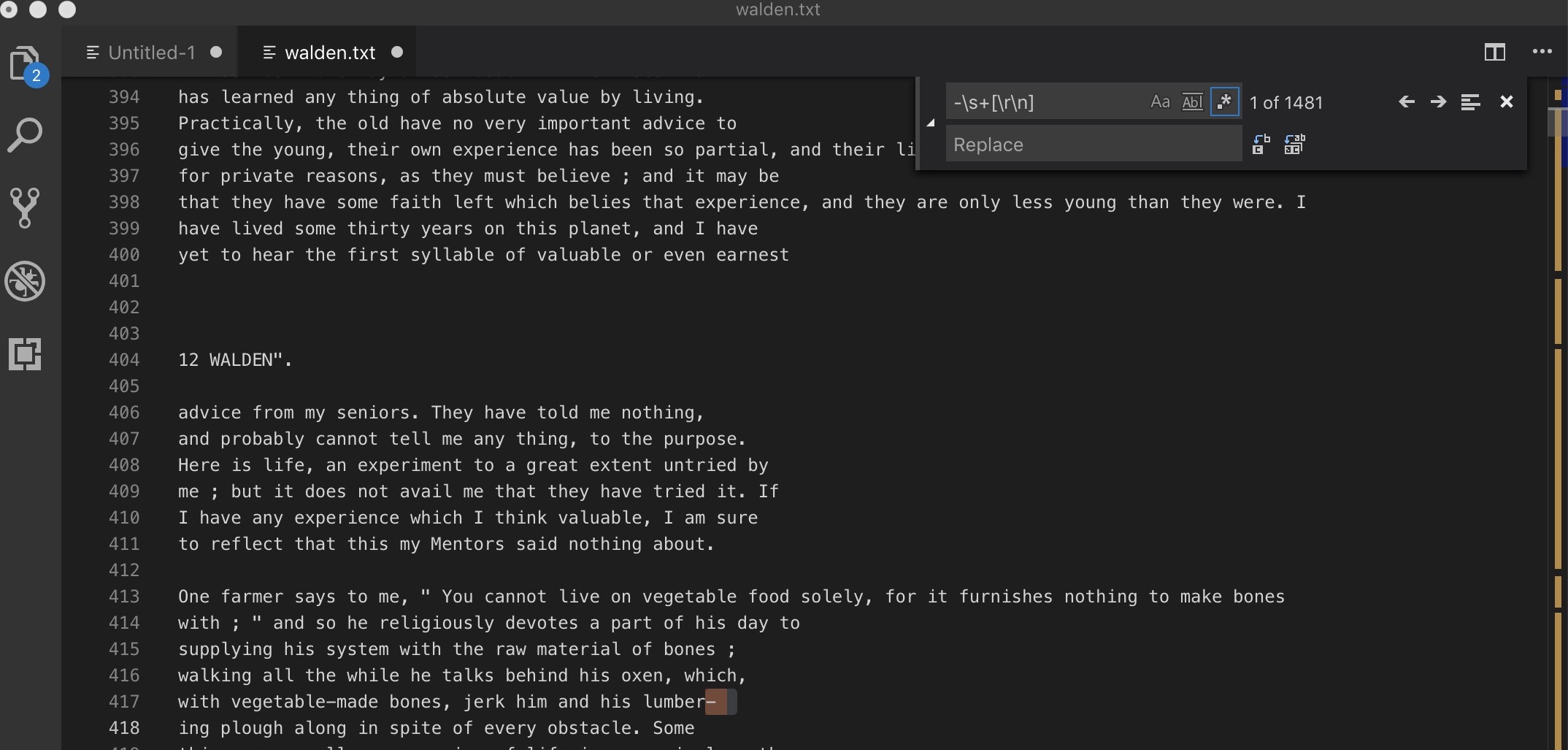
Remove hyphenated words at line breaks:
- In the search box, type:
-\s+[\r\n]-finds the hyphen,\s+finds one or more whitespace characters,[\r\n]replaces these characters and gets rid of the line break
- Replace all instances
The text still isn’t 100% clean, but we’ve managed to take out most of the page titles and consolidate hyphenated words, so our future analysis won’t be skewed.
Getting to Know Your Corpus

Text analysis allows us to look at the big picture and explore broad patterns that span large bodies of text.
However, this doesn’t absolve you from actually having to read some of the text you are analyzing.
In order to understand the outputs from the algorithms you run on your text, and to be sure that the results you are getting are actually valid, you need to be somewhat familiar with the text you are analyzing.