How to Use Topic Modeling
Why Use Topic Modeling?
- For exploration, hypothesis generation
- Playing around with text (even if you don’t know what you’re doing) can be an effective way to gain a new perspective on the texts you study
- The results may confirm your suspicions or yield surprising outputs that lead to further research
- For gaining insight into a corpus of text that is too large to read
When Does Topic Modeling Work Best?
Short answer: when interpreting large bodies of text
A very small corpus is unlikely to yield many useful or specific topics; larger corpora usually generate better results. This is because topic modeling is a machine learning process: the more training data the modeling program has, the more refined its topics become over time.
However, just because you can use topic modeling doesn’t necessarily mean you should. If you’re thinking seriously about whether it’s useful for your project, check out Matthew Kirschenbaum’s The Remaking of Reading: Data Mining and the Digital Humanities and Stephen Ramsay’s book, Reading Machines.
Input Data and Where to Find It
Before you start topic modeling, you’ll need to make sure you have the right type of data in the correct formats.
Plain Text For Input:
Structured Data vs. Unstructured Data
- Structured data: Data with fixed fields (key/value pairs, relations)
- Example: csv of names, phone numbers, dates, zip codes
- Unstructured data: No computer-readable structure or relationships between units of analysis
- Example: un-coded text
Topic modeling utilizes unstructured data, in the form of plain text files:
Plain text files are text files, i.e. contain only characters like a, 1, <, !, etc.
(Some characters might be hidden control characters, such as tabs and line breaks.)
Having text in this simple format enables it to be manipulated as data.
Where to find plain text files for topic modeling:
- Project Gutenberg
- Full text of thousands of free books. Text is usually fairly clean, but often little bibliographic information.
- Archive.org
- Full texts and scans of books, lots of different download options from epub to pdf, to plain text.
- HathiTrust
- Millions of digitized books, public domain and copyrighted. Cleanliness of text varies. More advanced features require institutional membership.
- DH Toychest
- Varied textual data compiled, cleaned, and organized by Alan Liu. These are good sets to use when you’re learning how to explore and experiment with topic modeling or any other type of text analysis.
Getting to Know Your Corpus
As a type of “distant reading,” topic modeling allows us to look at the big picture, enabling us to explore broad patterns that span large bodies of text.
However, this doesn’t absolve you from actually having to read some of the text you are modeling: In order to understand the outputs from the algorithms you run on your text (and to be sure that the results you are getting are actually valid), you need to be somewhat familiar with the text you are modeling.
- See Ben Schmidt, “When you have a MALLET, everything looks like a nail” for an example of what can happen when you’re not familiar with your data or the tools you’re using
Preparing Your Texts (cleaning, formatting, separating)
Selection and cleaning of corpora can be the most time- and labor-intensive aspects of topic modeling, and topic modeling outcomes depend on the quality and volume of data in the corpus:
- You’ll want to make sure your documents’ text is clean enough that you can interpret the topics that are produced. See this site’s Resources page for text cleaning techniques and tools.
Decide what you want your “document” to be (paragraph, chapter, letter, book, etc.), and split up your text accordingly.
What To Do With Your Topics
Interpret
Example Topics:
heard thought see looked look countenance made man good voice told called heard round knew spoke rose make looking began
night door long appeared passed light place hand heard present eyes time gave fear found person air sound left young
See Ted Underwood, Topic Modeling Made Just Simple Enough:
“I want this technique to point me toward something I don’t yet understand, and I almost never find that the results are too ambiguous to be useful. The problematic topics are the intuitive ones — the ones that are clearly about war, or seafaring, or trade. I can’t do much with those.”
Visualize
Make graphs using Excel or Tableau
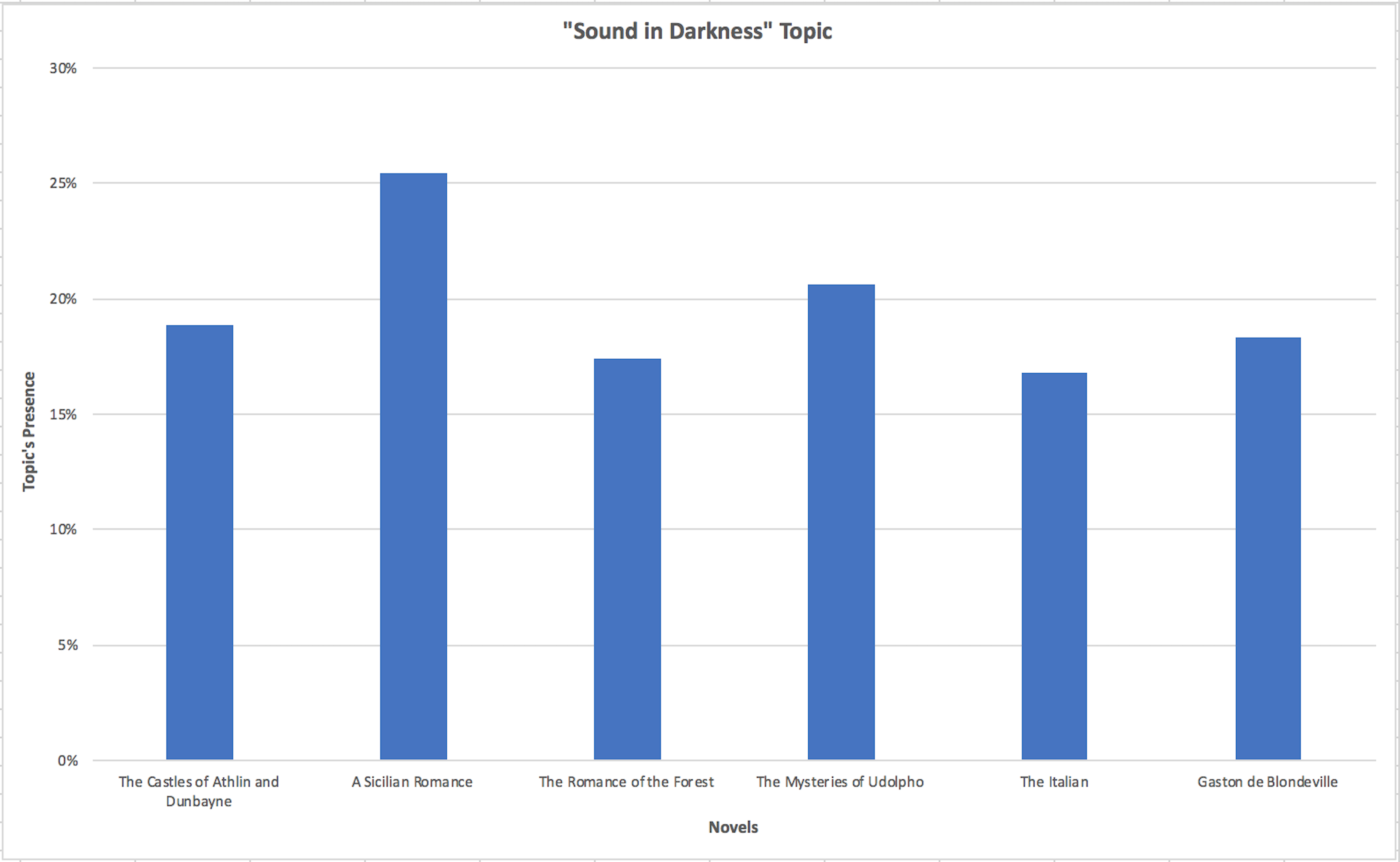
Examples
- Robert Nelson, Mining the Dispatch
- Cameron Blevins, Topic Modeling Martha Ballard’s Diary
- “‘The Spider’s Web’: An Analysis of Fan Mail from Amazing Spider-Man, 1963-1995”, by John A. Walsh, Shawn Martin, and Jennifer St. Germain, published in Empirical Comics Research: Digital, Multimodal, and Cognitive Methods
- Journal of Digital Humanities 2.1 (winter 2012)