What is Text Mining?
Mathematically rigorous inquiries into the relationship between words in a large corpus of text.
- Text mining helps researchers detect patterns and connections in large volumes of textual material, allowing them to draw conclusions from a large body of text that they would not be able to otherwise read, synthesize, and incorporate into their scholarship.

Text Mining is often about counting words:
- Words matter
- Words hang together in interesting ways…

Text Mining involves pattern matching:
- Identify similarities in a large corpus
- Overarching trends across a whole set of texts
- Association within sets
- Categorization of new items being added to a set
- Identify differences
- Outliers and anomalies between texts
- Combine the two
- Clusters of similar groups with indications of outlier groups

A Few Types of Text Mining:
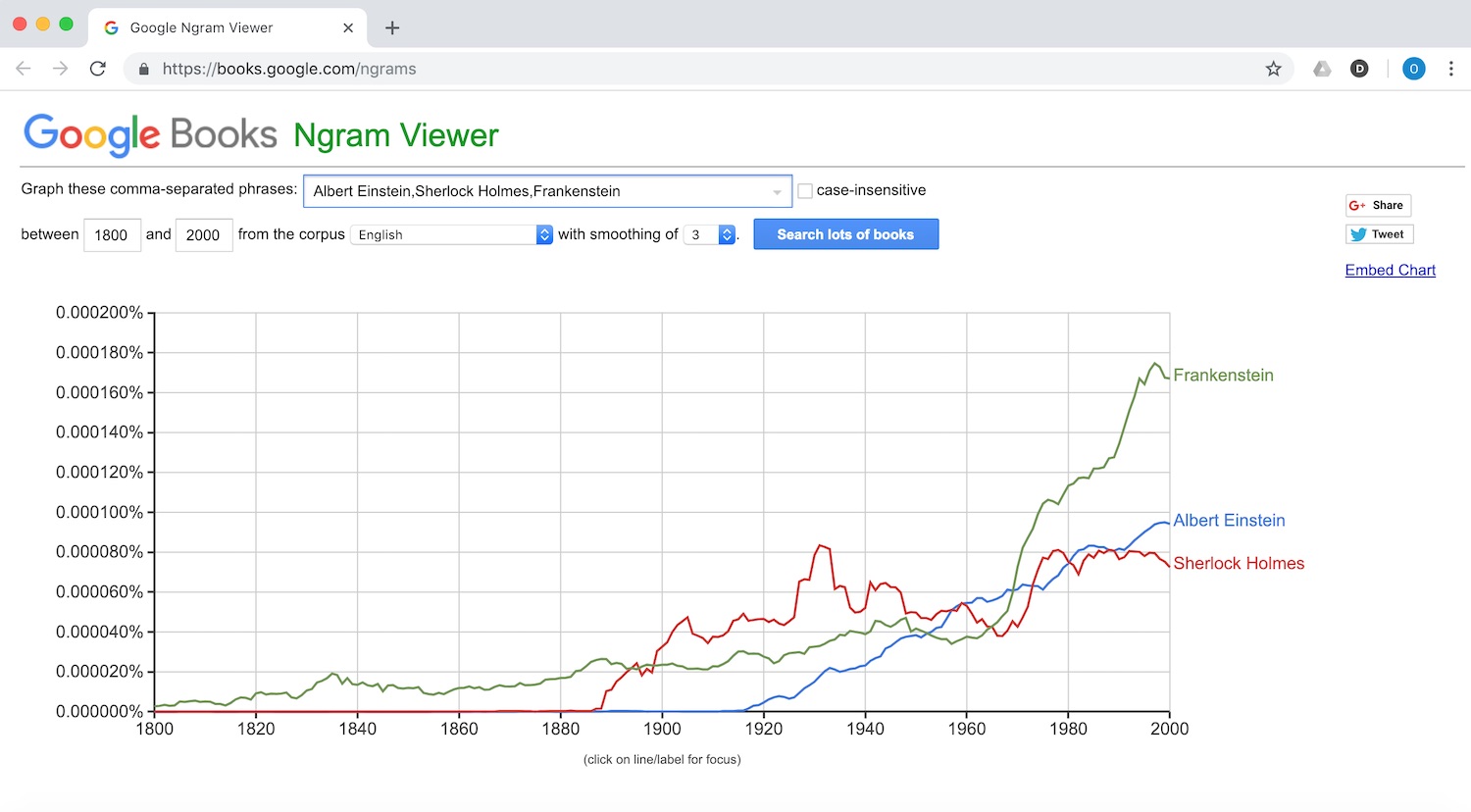
N-grams
- Analyzing a text for a sequence of words
- Possible use: Change-over-time analysis
- Example: https://books.google.com/ngrams
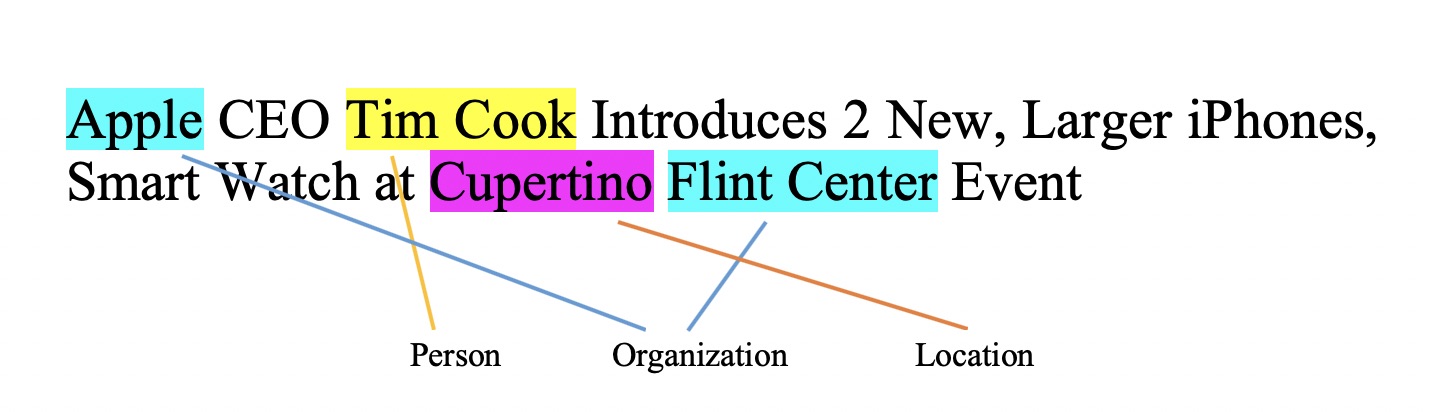
Named Entity Recognition
- Part-of-speech tagging
- Possible use: Extract and categorize entities such as person names, organizations, etc.
- Example: Six Degrees of Francis Bacon
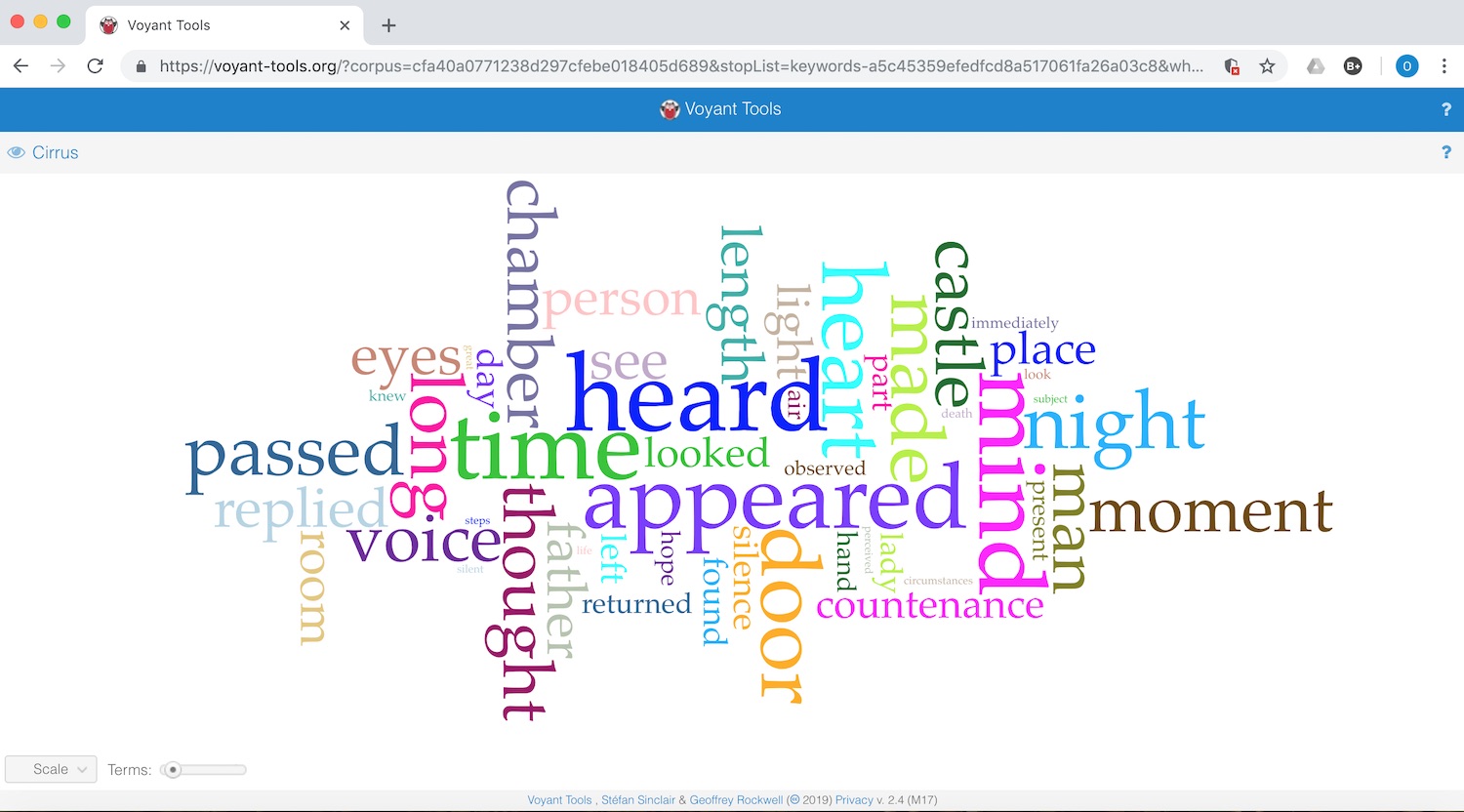
Word Clouds
- Simple approach to analytical partitioning
- Elements of data visualization: size, color, distance of words can be used as elements of argumentation
- Example: TagCrowd.com or WordItOut (try it using this text)
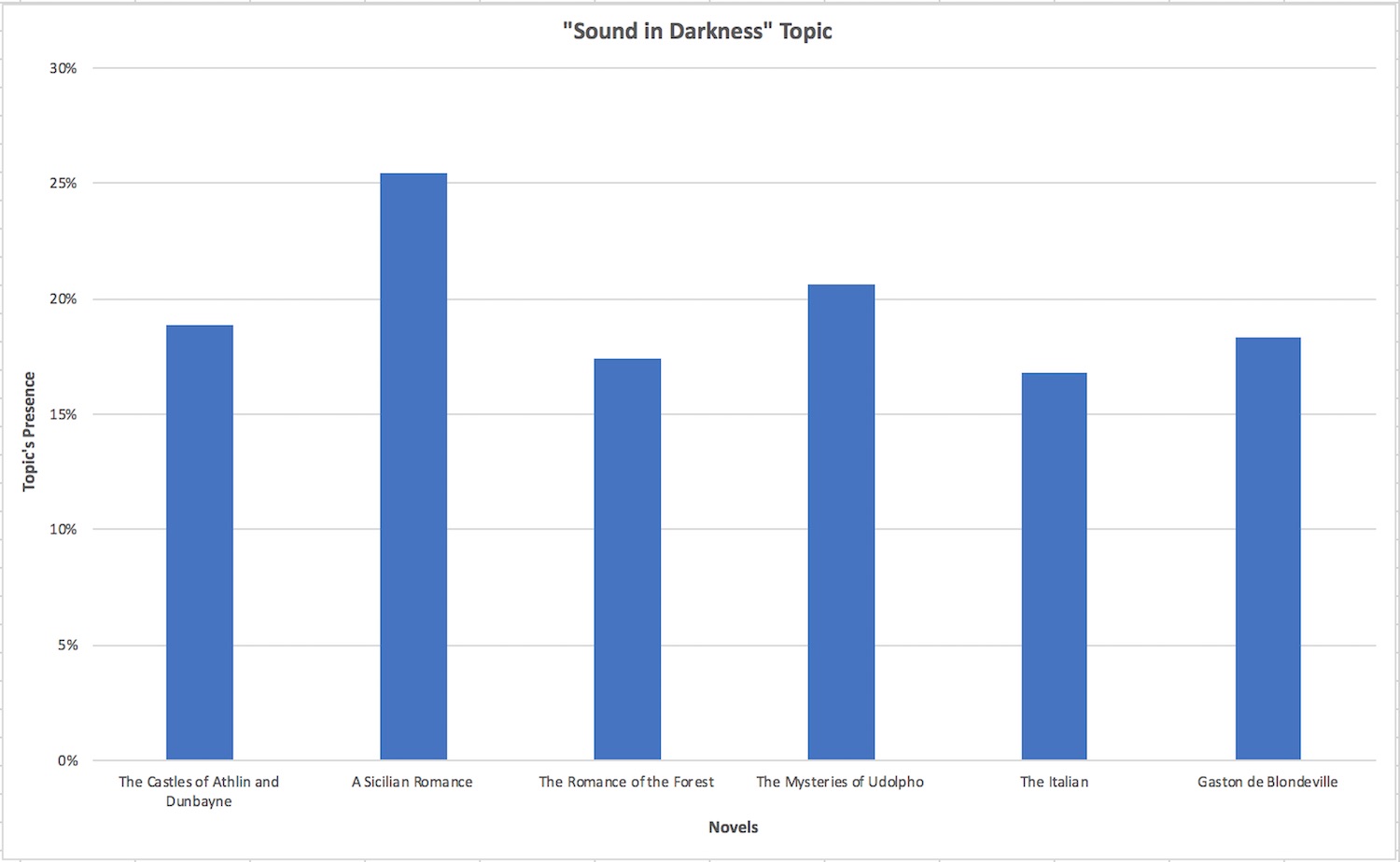
Topic Modeling
- Comparing large trends in corpora
- Iterative algorithm identifies a set of topics related to a set of documents
- Example: Mining the Dispatch


Limitations and Errors in Text Mining:
- Be cognizant of your question as you gather data
- Data lies (if it’s collected in inappropriate ways). What’s in your set?
- Data from NY and LA between 1920-1940 and 2000-2010 can’t be used to make claims about patterns in the US between 1900 and 2010
- Be aware of the limits of text mining
- You need computer readable files
- Be aware of what you can munge
- If your transcription/OCR (Optical Character Recognition) always turns the word “like” into the word “lilce”… consistency in errors is still consistency